Paperless-ngx - Adulting in 2023
This year, I switched to hosting my own installation of Paperless-ngx, and it has leveled up my paperless adulting life in several ways.
Since about 2015 I was using Evernote as a home for paperless filing via NoteSlurp, which is a bespoke set of tools I wrote to efficiently ingest my scanned documents from Linux. I’ve been using some form of Evernote (originally their Mac OS application with filesystem sync) since around 2014 for my paperless filing needs, and it served me well for some time. I chose Evernote years ago as their OCR seemed to be unmatched (specifically better than other cloud drive solutions), they had tools for auto-synchronizing as well as published APIs, and there were a variety of powerful organization schemes available with tagging. Evernote did a few things, and did them all well, so it was an easy subscription fee to pay for.
Evernote Woes #
However, in more recent years I’ve grown to like a lot of things about Evernote less and less:
- The OCR seems to have faltered, and is no longer better than even those things freely available with open-source tools
- Their new web and mobile experiences are atrociously slow, with an incredible amount of up-front SPA bloat, and seemingly a need to rebuild the entire experience every time I open the app
- Even if the new experiences were fast, they aren’t exactly out of your way and pleasant to use, most of the newer features they’ve added have been for an audience that is clearly not me
- They have risen prices on me three times in the last 8 years, and will not stop trying to upsell me with ads for their other tiers, which I have no interest in
- Their API is stagnant and missing important features to enable my Linux-centric workflow
- The sheer number of “bespoke” tools I’ve had to scrap together in NoteSlurp has increased multiple times a year
A Workflow Refined Over Time #
To understand what I was doing and for what I needed a replacement, it might be worth revisiting my Evernote workflow:
- Upon receiving a document I wanted to keep, I would scan it with my ADF or similar scanner, which would place it as a PDF in a directory on my local server
- Periodically I would visit that directory, and I would rename the various files with a special “tag format” that Noteslurp could recognize, adding keywords that would automatically add Evernote tags
- Noteslurp would scan that file on a periodic cron basis, ingesting documents into Evernote as an “empty” document with the title of the file, and a single attachment of the file itself
- I also would use the “Evernote to Email” feature by occasionally forwarding emails I received that were important (including those with inline invoices or statements) to the Evernote “ingest” email address for my account.
- Within Evernote, I had tags for things like
School,Work,Travel,Medical,Retirement, and others. - Additionally, I also had date-based tagging in evernote, such as
2022and2022-01, which helped with finding documents based on when they were received. - I had only two primary “filing” notebooks in Evernote, with
InboxandCabinet. Inbox implied “yet to be officially filed”. Cabinet, as the name implies, was the permanent home of documents. (I used Evernote for some other “research and journaling” purposes, but I’m not including that in this analysis) - I also built “note-filing” tooling in Noteslurp to allow me to quickly walk the documents in Inbox, look for revisions I wish to make (such as adding tags, removing tags, etc), and “filing” meaning moving the document from
InboxtoCabinet
This workflow mostly worked and served me well for several years, but as mentioned above it took a lot of work over the years to keep it stable, and I have recently suffered due to odd choices at Evernote itself.
Exploring New Options #
With the release of TrueNas Scale Bluefin, I decided it was time to revisit my home NAS situation, which was really just some extra drives in my desktop Linux machine, and needed some more “official” treatment. Along with that, I decided to check out various purpose-built paperless filing tools. I did some trial installations and experiments with several that could easily be hosted on my new NAS that were recommended by Awesome Self-Hosted - here are my thoughts on each:
- PaperMerge - PaperMerge has a lot of potential. The intake pipeline is very rich and the ability to work with so many document types, document merging, document versioning, and others made it very compelling. However, at the time of my review, v2.0 and v2.1 both existed, and 2.1 is a rewrite of 2.0 that has a fundamentally different storage system, and is missing features. In other words - as best as I can tell, in a year this might have been the winner
- Teedy - Teedy has a lot of compelling features as well, though I didn’t like the “Document vs Attachment” hierarchy concept as the default, which made creating documents manually quite slow (most of the time, my attachments are my documents), though I did like that at the time I reviewed it, it could ingest emails, which is a very common workflow with me and Evernote
- DocSpell - This is an interesting project, but is simply not as far as long as some of the others in certain places
- Paperless-ngx - The UI for this is the most efficient for intaking documents, and it matches my “80%” case of my single attachments being “the document”. The OCR is very solid, and adding support for Windows-esque document types is a simple case of linking to a few other Docker images (Tika and Gotenberg). The biggest issue at my trial of this project was that the email support only could ingest attachments, and could not ingest raw emails as if they were documents themselves
As if reading my mind, a new release of Paperless-ngx became available with e-mail ingestion support about a week after I gave it my first trial installation. As a result, it became the clear winner and I chose to jump right in. After ingesting more than 7000 PDFs, emails, and other documents from my archive, I can honestly say it is an ideal replacement for my previous workflow, and only adds efficiencies.
What Paperless-ngx Offers #
Here are a few highlights of the experience for me:
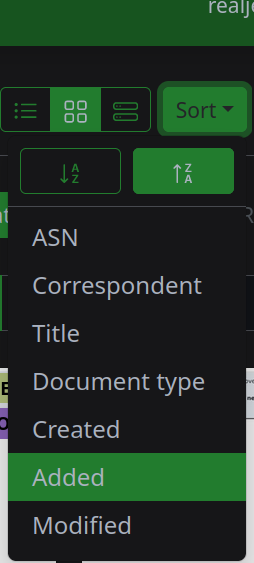
- Paperless documents have several aspects with which they are categorized, including
Correspondent,Document Type,Created Date,Added Date,ASN,Title, and of courseTags. By having several different “official” ways to categorize documents, more sorting and filtering features become available. - Paperless supports default labels, which allow you to mark all documents with a special
TODOlabel when ingesting, so you can find all documents that require categorization before permanently archiving (a key aspect of my Evernote workflow) - In my experience, Paperless OCR is very accurate, and can handle even pretty unstable documents, such as those ingested with an image scanner and somewhat blurry camera snaps
- Upon viewing a document in the front-end, the ingested version has a copy-pasteable text layer - so the OCR is applied as a text layer in the viewable PDF, which is instantly more usable
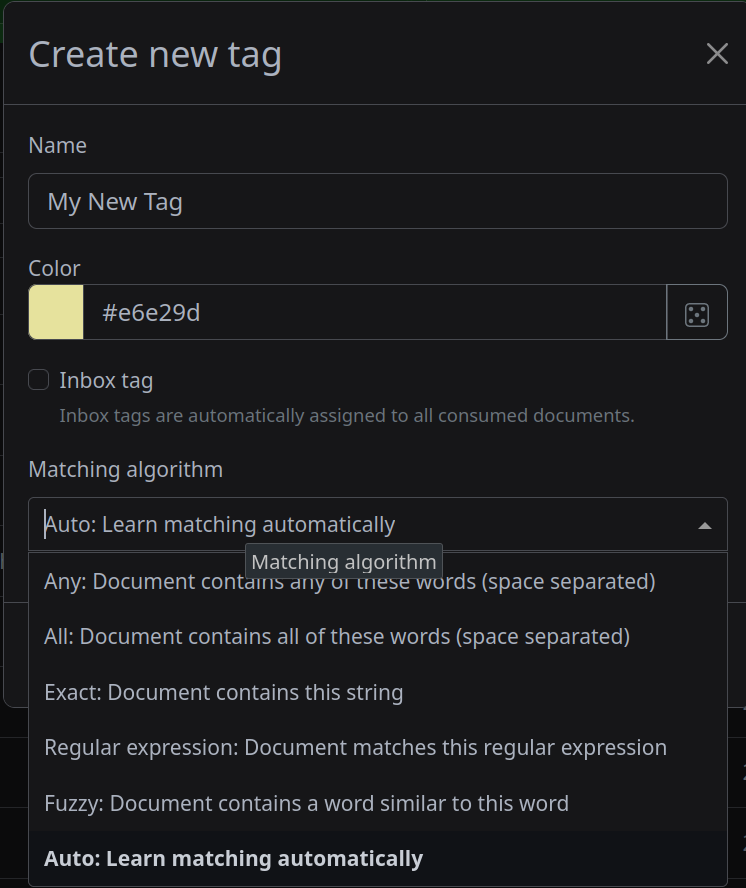
- There are many ways to use the “results” of an OCR to auto-tag the document. Manual association is possible for document types, correspondent, and tags, such as “if this word or regex matches apply these tags”, but there is also an “Auto” version that, as more documents are added and manually fixed by you, becomes smarter and “guesses” based on prior/similar documents
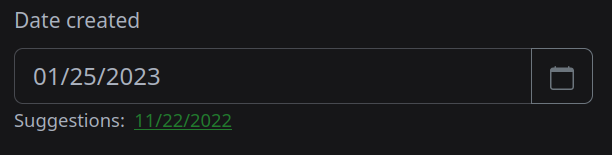
- OCR auto-association also applies to dates, which means it is (sometimes shockingly) good at finding a date in the document such as a “Payment Due Date” or “Invoice Date” and assuming that as the “Document Created Date”, which was tremendously useful when importing from 7+ year old PDFs
- As with my manually built tooling, Paperless can scan a directory periodically (even something like NFS on a schedule) to look for documents to import, and provides good feedback on progress as well as ingestion success or failure
- Unlike Evernote which required forwarding emails, Paperless supports scanning an IMAP folder. This means you can still of course use email forwarding if you have a dedicated email address, but it also means you can simply drag-and-drop emails into a folder to have them ingested. And, once ingested, Paperless will automatically move the email to a different folder, mark it read, or even delete it based on a variety of rule options
- Paperless also keeps your “original” document that was uploaded on a filesystem of your choosing, and in a directory hierarchy of your choosing, which can be selected on a per document basis. This means you can specify for documents to be stored in original format as
"year"/"month"/"title"."ext"or something entirely different. As someone that just left an attachment walled garden, having my documents stored in an easy to access way in case this product vanishes is a huge win for me - Paperless supports forward auth configurations for tools like Authelia or Authentik, meaning you can put an ingress in front of them with auth middleware that supports MFA or even WebAuthN/Passkeys, and never have to auth directly with the product
- When “editing” a document (which happens a lot when you are bulk migrating 7000 documents), the suggestions it provides can be quite handy, especially in cases where it may have found 2, 3, or 4 dates that might be the “created” date, and it presents the document on the same screen so you can review it while tagging
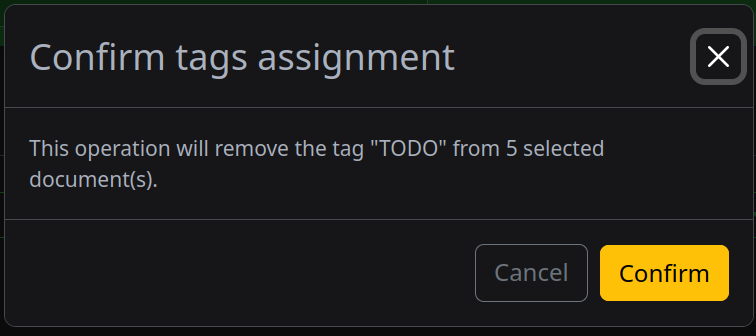
- Bulk updates are quite easy too, and can span multiple pages, so if you find 200+ documents that you can tell it scanned and tagged mostly correctly, you can do a bulk edit to all of them adjusting certain things, and removing the
TODOtag as appropriate - With Tika and Gotenberg it can scan all variety of Windows-garden documents like Word docs, which often come from my childrens’ school, for better or worse
Screenshots #
Here are some screenshots to illustrate some of these features:
For those interested in considering Paperless, I highly recommend reviewing their recommended workflow, which if I were to paraphrase, sounds a lot like my Noteslurp+Evernote workflow from above:
- Regularly put documents to ingest in a physical location in your home
- If you plan to keep the physical copy, write a number on the document to help correlate the real document to the paperless one (your personal ASN)
- Scan the document and put it in the Paperless ingestion folder
- Keep or toss the physical depending on importance
- Configure Paperless to tag all ingested documents with “TODO”
- Create a “TODO” view in paperless of all documents that need to be filed
- Periodically work through the TODO list, verifying dates, correspondents, ASNs, and tags, filing by removing the TODO tag
- Over time, refine and improve the various matching rules for tags, document types, and correspondents
The only subtle revision I make is that I organize my physical documents by year, and I keep a filing box in my basement for every year (2017, 2018, 2019, 2020, 2021, 2022), and I start collecting the current year (2023) next to my scanner. When the year transitions, I take the box down, and start a new one, and shred the oldest.
Summary #
Overall this has been an excellent experience to take back control over my own documents, refine my process for filing, and drop some cloud hosting costs for a product I no longer believed in. I highly recommend others explore it, and if there is interest, I’ll definitely spend more time showing how to set this up with TrueNas Scale so that it has all the desired bells and whistles.
That said, this didn’t completely replace my use of Evernote. I also used it for journaling, research documents, recipe tracking, and more. Each of these got some attention too, so i hope to spend more time talking about replacements in those spaces in the coming days.